If you're using the HTTP protocol in everday Internet use you are usually only using two of its methods: GET and POST. However HTTP has a number of other methods, so I wondered what you can do with them and if there are any vulnerabilities.

One HTTP method is called OPTIONS. It simply allows asking a server which other HTTP methods it supports. The server answers with the "Allow" header and gives us a comma separated list of supported methods.
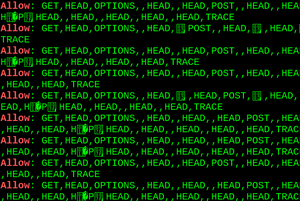
A scan of the Alexa Top 1 Million revealed something strange: Plenty of servers sent out an "Allow" header with what looked like corrupted data. Some examples:
Allow: ,GET,,,POST,OPTIONS,HEAD,,
Allow: POST,OPTIONS,,HEAD,:09:44 GMT
Allow: GET,HEAD,OPTIONS,,HEAD,,HEAD,,HEAD,, HEAD,,HEAD,,HEAD,,HEAD,POST,,HEAD,, HEAD,!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"
Allow: GET,HEAD,OPTIONS,=write HTTP/1.0,HEAD,,HEAD,POST,,HEAD,TRACE
That clearly looked interesting - and dangerous. It suspiciously looked like a "bleed"-style bug, which has become a name for bugs where arbitrary pieces of memory are leaked to a potential attacker. However these were random servers on the Internet, so at first I didn't know what software was causing this.
Sometimes HTTP servers send a "Server" header telling the software. However one needs to be aware that the "Server" header can lie. It's quite common to have one HTTP server proxying another. I got all kinds of different "Server" headers back, but I very much suspected that these were all from the same bug.
I tried to contact the affected server operators, but only one of them answered, and he was extremely reluctant to tell me anything about his setup, so that wasn't very helpful either.
However I got one clue: Some of the corrupted headers contained strings that were clearly configuration options from Apache. It seemed quite unlikely that those would show up in the memory of other server software. But I was unable to reproduce anything alike on my own Apache servers. I also tried reading the code that put together the Allow header to see if I can find any clues, but with no success. So without knowing any details I contacted the Apache security team.
Fortunately Apache developer Jacob Champion digged into it and figured out what was going on: Apache supports a configuration directive
Limit that allows restricting access to certain HTTP methods to a specific user. And if one sets the Limit directive in an .htaccess file for an HTTP method that's not globally registered in the server then the corruption happens. After that I was able to reproduce it myself. Setting a Limit directive for any invalid HTTP method in an .htaccess file caused a use after free error in the construction of the Allow header which was also
detectable with Address Sanitizer. (However ASAN doesn't work reliably due to the memory allocation abstraction done by APR.)
FAQ
What's Optionsbleed?
Optionsbleed is a use after free error in Apache HTTP that causes a corrupted Allow header to be constructed in response to HTTP OPTIONS requests. This can leak pieces of arbitrary memory from the server process that may contain secrets. The memory pieces change after multiple requests, so for a vulnerable host an arbitrary number of memory chunks can be leaked.
The bug appears if a webmaster tries to use the "Limit" directive with an invalid HTTP method.
Example .htaccess:
<Limit abcxyz>
</Limit>
How prevalent is it?
Scanning the Alexa Top 1 Million revealed 466 hosts with corrupted Allow headers. In theory it's possible that other server software has similar bugs. On the other hand this bug is nondeterministic, so not all vulnerable hosts may have been caught.
So it only happens if you set a quite unusual configuration option?
There's an additional risk in shared hosting environments. The corruption is not limited to a single virtual host. One customer of a shared hosting provider could deliberately create an .htaccess file causing this corruption hoping to be able to extract secret data from other hosts on the same system.
I can't reproduce it!
Due to its nature the bug doesn't appear deterministically. It only seems to appear on busy servers. Sometimes it only appears after multiple requests.
Does it have a CVE?
CVE-2017-9798.
I'm seeing Allow headers containing HEAD multiple times!
This is actually a different Apache bug (
#61207) that I found during this investigation. It causes HEAD to appear three times instead of once. However it's harmless and not a security bug.
Launchpad also has
a harmless bug that produces a malformed Allow header, using a space-separated list instead of a comma-separated one.
How can I test it?
A simple way is to use Curl in a loop and send OPTIONS requests:
for i in {1..100}; do curl -sI -X OPTIONS https://www.google.com/|grep -i "allow:"; done
Depending on the server configuration it may not answer to OPTIONS requests on some URLs. Try different paths, HTTP versus HTTPS hosts, non-www versus www etc. may lead to different results.
Please note that this bug does not show up with the "*" OPTIONS target, you need a specific path.
Here's a
python proof of concept script.
What shall I do?
If you run an Apache web server you should update. Most distributions should have updated packages by now or very soon. A patch can
be found here. A patch for Apache 2.2
is available here (thanks to Thomas Deutschmann for backporting it).
Unfortunately the communication with the Apache security team wasn't ideal. They were unable to provide a timeline for a coordinated release with a fix, so I decided to define a disclosure date on my own without an upstream fix.
If you run an Apache web server in a shared hosting environment that allows users to create .htaccess files you should drop everything you are doing right now, update immediately and make sure you restart the server afterwards.
Is this as bad as Heartbleed?
No. Although similar in nature, this bug leaks only small chunks of memory and more importantly only affects a small number of hosts by default.
It's still a pretty bad bug, particularly for shared hosting environments.
Updates:
Analysis by Apache developer William A. Rowe Jr.
Distribution updates:
Gentoo:
Commit (2.2.34 / 2.4.27-r1 fixed),
Bug
NetBSD/pkgsrc:
Commit
Guix:
Commit
Arch Linux:
Commit (2.4.27-2 fixed)
Slackware:
Advisory
NixOS:
Commit
Debian:
Security Tracker,
Advisory (2.4.10-10+deb8u11, 2.4.25-3+deb9u3)
Ubuntu:
Advisory (2.4.25-3ubuntu2.3, 2.4.18-2ubuntu3.5, 2.4.7-1ubuntu4.18)
Media:
Apache-Webserver blutet (Golem.de)
Apache Webserver: "Optionsbleed"-Bug legt Speicherinhalte offen (heise online)
Risks Limited With Latest Apache Bug, Optionsbleed (Threatpost)
Apache “Optionsbleed” vulnerability – what you need to know (Naked Security)
Apache bug leaks contents of server memory for all to see—Patch now (Ars Technica)

{kind=link}
.svg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}